
With the third part of our journey, we will uncover the purpose of the hashing function, share a ride on the Avalanche effect, discover the widespread use of hashes across the blockchain field, and compare two commonly used hashing algorithms in a clash of cryptographic titans.
¶ Why do blockchains need hashing functions?
As blockchain and crypto enthusiasts, you deal with hashes a lot. Your wallet address, a transaction ID, a block ID - these are all outputs of hashing functions. Hashing functions are primitives that also provide deterministic behavior of nodes with respect to transaction order. That primitive is used to build a so-called Merkel Tree in Bitcoin or a Trei in the case of the RSK network.
Hashes look like a random set of characters. However, a hash isn't random at all. The value makes little sense to a human reader because it's intended to be read and interpreted by a computer.
The reason for their use in blockchain technology is their versatility for the purposes of data integrity and privacy.
- Hashes protect data integrity by hiding and encoding the original message to a unique string, and thus create, in a way, the element of best pseudonyms on the blockchain while allowing everything to remain transparent.
A hash algorithm is a mathematical function that transforms any input into a fixed size output. To be cryptographically secure and usable in blockchain technology at the same time, the hash function needs to be collision-resistant, which means that it is practically impossible to find two inputs that produce the same output. While a hashing function is a cryptographic function, it's not encryption. Encryption works with a system where you have an input, encryption formula, a key, and an encrypted output. By knowing the encrypted input and the key, you can decrypt the output and obtain the original message. A hashing function, in contrast to encryption, works as a one-way function; you are not able to find the original message when the only thing you know is the hash. Likewise, anyone with the original message and the hashing algorithm will produce the same hash.
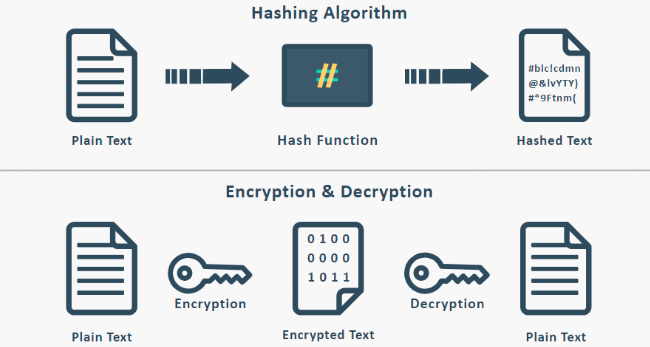
While the input data of a hash can have any length, from a single character to the whole content of 33 million books of the US Library of Congress, the output is always 32 bytes (SHA-1), or 64 bytes (SHA-2) long discrete numbers. That’s a number between 0 and 4,294,967,295 for a 32-byte hash and between 0 and 9,223,372,036,854,775,807 for a 64-byte hash. That is more possibilities than all the grains of sand in 10 Sahara deserts. The possibility of two different inputs resulting in the same hash is known, but the probability of this event is so small that it doesn't even matter. The feature that preserves the fixed length of a hashing function output is provided by compression functions, which are a part of a hashing algorithm. As with the blockchain itself where new blockchain nodes need to synchronize themselves with the rest of already running full nodes first, a hashing function is underlined by the determinism principle - the same message hashed with the same function will always return the same hashed result (no matter the place or time). An important aspect of secure hashing functions is: if you change only a single character of the input, the resulting hash will be something completely different. At the same time, two similarly-looking hashes will have vastly different inputs.
Example:
|
The SHA-256 hash of the word bear is x but the SHA-256 hash of the word bare is y. Note the difference between the simple integers. 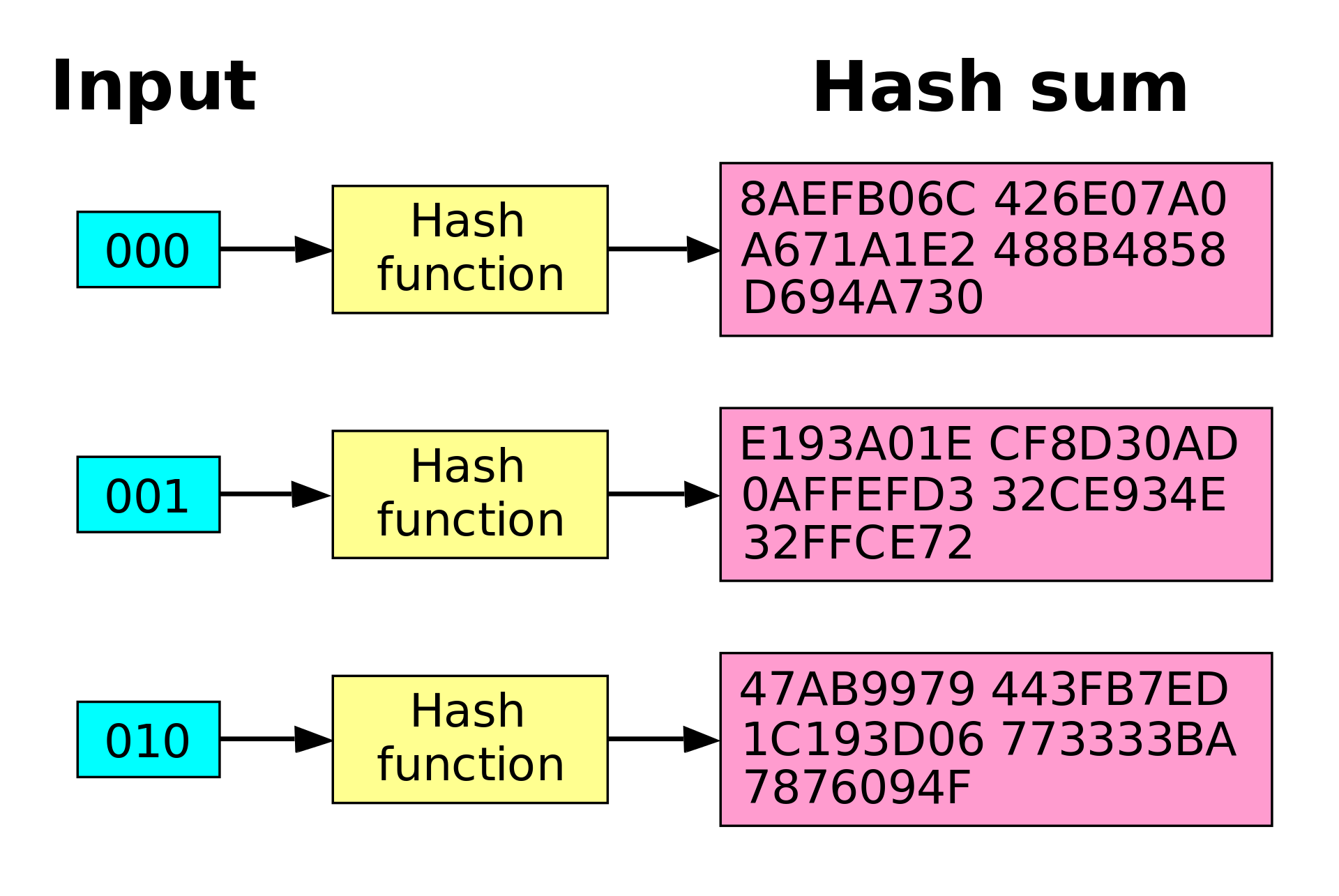 |
Bitcoin uses the SHA-256 hash algorithm to generate verifiably "random" numbers in a way that requires a predictable amount of CPU effort. Generating a SHA-256 hash with a value less than the current target solves a block and wins you some coins.
|
Reminder from the previous part:
|
SHA is the abbreviation of "Secret Hashing Algorithm". It’s not a single hashing algorithm, but a family of very different functions, of which only SHA-2 and SHA-3 are recommended for use today. This family of hashing functions is managed by NIST, the U.S. institute of standards and technology.
An output of a hashing function is always a discrete number described as a set of binary units: zeros and ones. Typically, the hash is shown in hexadecimal form. So, rather than having digits from 0 to 9, digits are from 0 to f (where “a” is 10 and “f” is 15). That is why - even though a transaction id or wallet address is a just number - you can spot some letters in it, too.
¶ How does the SHA algorithm work?
SHA-1 bears a striking similarity in structure to MD4 and MD5 hashing algorithms that were used earlier. SHA-1 =160bits, 5x32bit words, four bytes each (definition from the standard). When hashing with SHA-2, we have 256 or 512 bit long strings constructed with zeros and ones.
Input data is sorted via a loop into 256 or 512-bit large blocks of data, depending on the used SHA-2 variation, one at a time until the file is expanded. If a message is large enough to fill exactly one block (eg. 512 bits long), the hash loop will run only once. This means that the final output of the hashing function will be updated once. If the message is longer, it requires more loops; each loop brings a new block of data into the hashing function. A compression function, which is the standard part of SHA or MD hashing functions, then follows with compression of looped data.
The compression function takes this data and a bit of the message and turns it into another set of "n" values, which is repeated over the whole message. In our case, this will happen only once, since we have a message of the exact same length as a potential space in the hashing block. Updating the internal state with a compression function is called a Merkel down guard construction.
When the message isn't long enough to fill exactly one 512 bit block, padding has to be used. Padding means that a space that is left in the block is filled by binary notation, which represents the length of the message in the block. The padding scheme ensures that messages of the same length and messages that end in the same or very similar way don't share the same padding, and thus the final hash.
¶ Why is SHA-2 more secure than SHA-1?
The difference between SHA-1 and SHA2 is in the slightly different compression functions and the longer internal state; it's 256 or 512 bits instead of SHA-1's 160 bits.
SHA-1 is 160 bits, which is quite long. This means that the chance of collision - of you stumbling across two messages that hash to the same result - is roughly 2^80. That's a very long time, somewhere around 12 million GPU years. But the compression function of SHA-1 is not so good, and it is possible for attackers to reduce this to 2^60, which is brute-force hackable by people with a lot of time and money.
SHA-2 is similar to SHA-1 with slightly different compression functions, and the internal state is longer. It's 256 or 512 bits with SHA-2, so your starting point is trying to brute force something like 2^128, which is vastly more than 2^80 and even more than 2^60.
¶ The risk of collision
The critical point we focus on with hashing function security is the possibility to create a collision. A collision is when you find two distinct messages that are hashed to the same value; meaning - two different inputs share the same hashed fingerprint. This collision can be produced by a random accident or by a brute-force guessing attack. In many protocols, however, collisions don't matter. What is essential is the resistance to second preimages. A second preimage is like a collision, except that the attacker does not get to choose one of the messages. Instead, the attacker is challenged to find a colliding pair of messages, the first message being set by the attacker’s target (for example, a cryptographic certificate generated by a certificate authority). Finding second preimages is therefore a lot harder than finding collisions.
¶ The SHA-1 constructed collision
The collision from February 23, 2017, was merely the first known case of actually running the attack. In 2013, Marc Stevens published a paper that outlined a theoretical approach to create a SHA-1 collision. The first phase of the 2017 collision simulation started by creating a PDF prefix specifically crafted to generate two documents with arbitrary distinct visual contents, but that would hash to the same SHA-1 digest. To overcome some computation challenges while building this theoretical attack in practice, a simulation team leveraged Google’s technical expertise and cloud infrastructure to compute the collision, one of the largest computations ever completed.
|
Computation scale of the attack simulation [1]:
|
While those numbers seem very large, the SHA-1 shattered attack is still more than 100,000 times faster than a brute force attack which remains impractical.
SHA-1 seems still very very robust for second preimages, and any protocol that uses SHA-1 and relies on second preimage resistance can keep on doing so safely for the time being. It is, however, advisable to migrate to SHA-256, which is the hashing algorithm used by Bitcoin.
- Since 2005, SHA-1 has not been considered secure against well-funded opponents; as of 2010 many organizations have recommended its replacement.
- NIST formally deprecated the use of SHA-1 in 2011 and disallowed its use for digital signatures in 2013.
- Microsoft has discontinued SHA-1 code signing support for Windows Update on August 7, 2020.
Congratulations. You made the third step in becoming a blockchain expert.
Originally post on Hackernoon -July 16th, 2021
Footnotes:
[1] The official Google announcement about the SHA-1 collision success
¶ Navigation
- Part 1: Determinism
- Part 2 : Mining, Miners, and the Proof of Work algorithm
- Part 3: Hashing Functions
- Part 4: The 51% Attack
- Part 5: Forks
- Part 6: Blockchain Transactions
- Part 7: Inside a Bitcoin Block
- Part 8: Smart Contracts
- Part 9: Blockchain's impact on the world
- Back to Sovryn Dojo